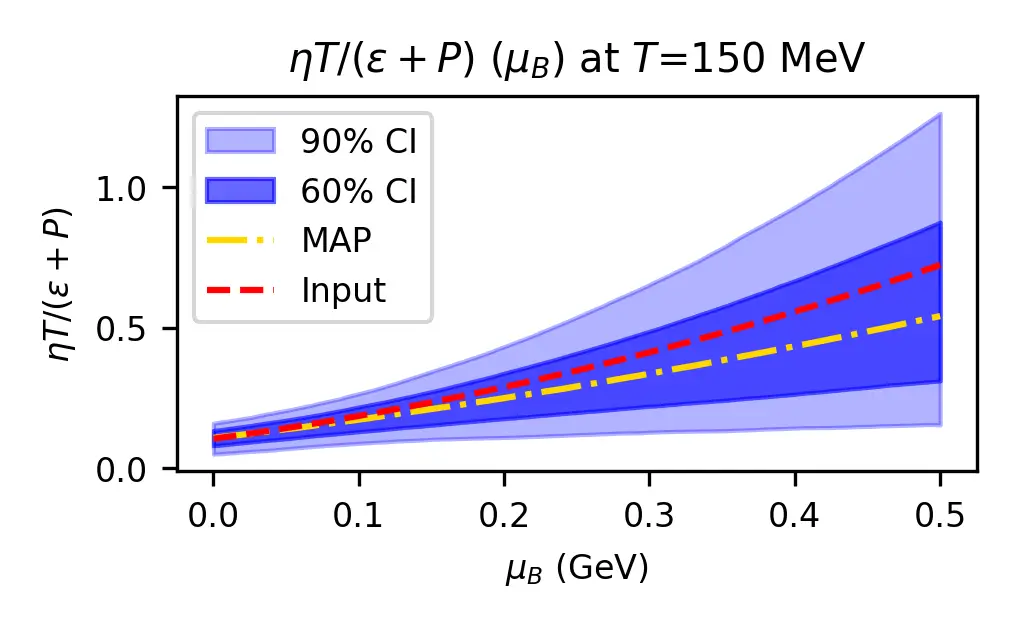
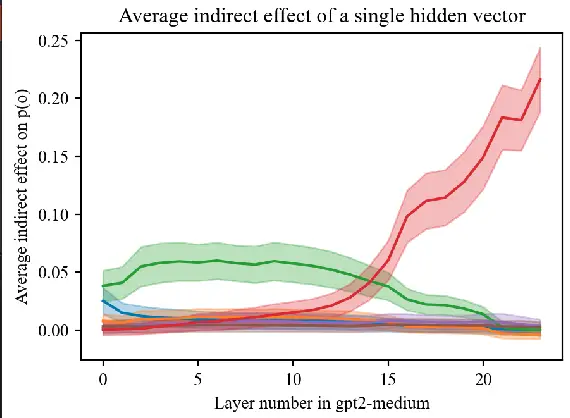
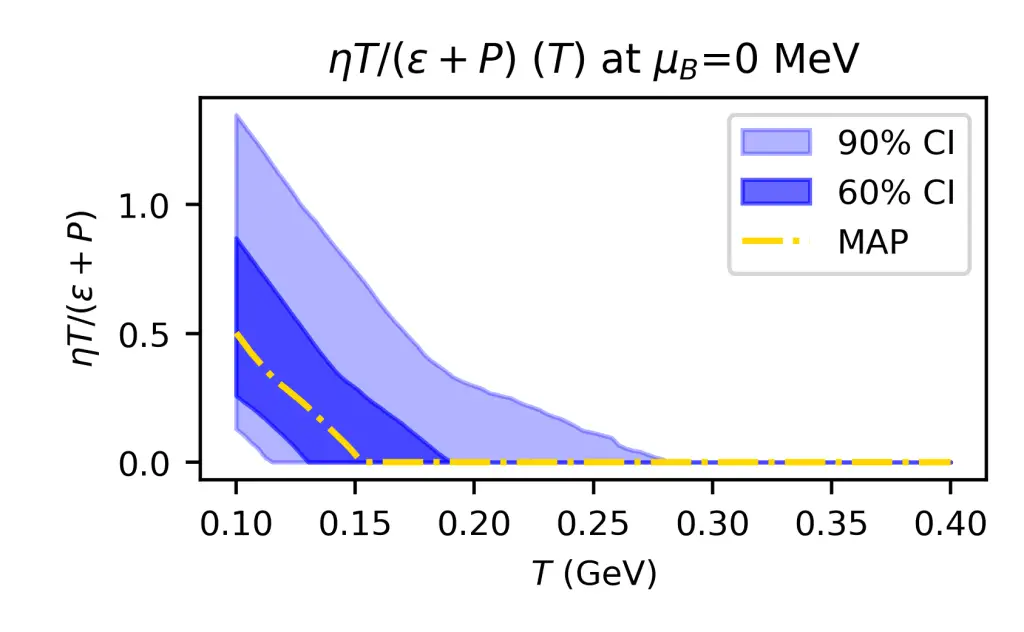
About Me
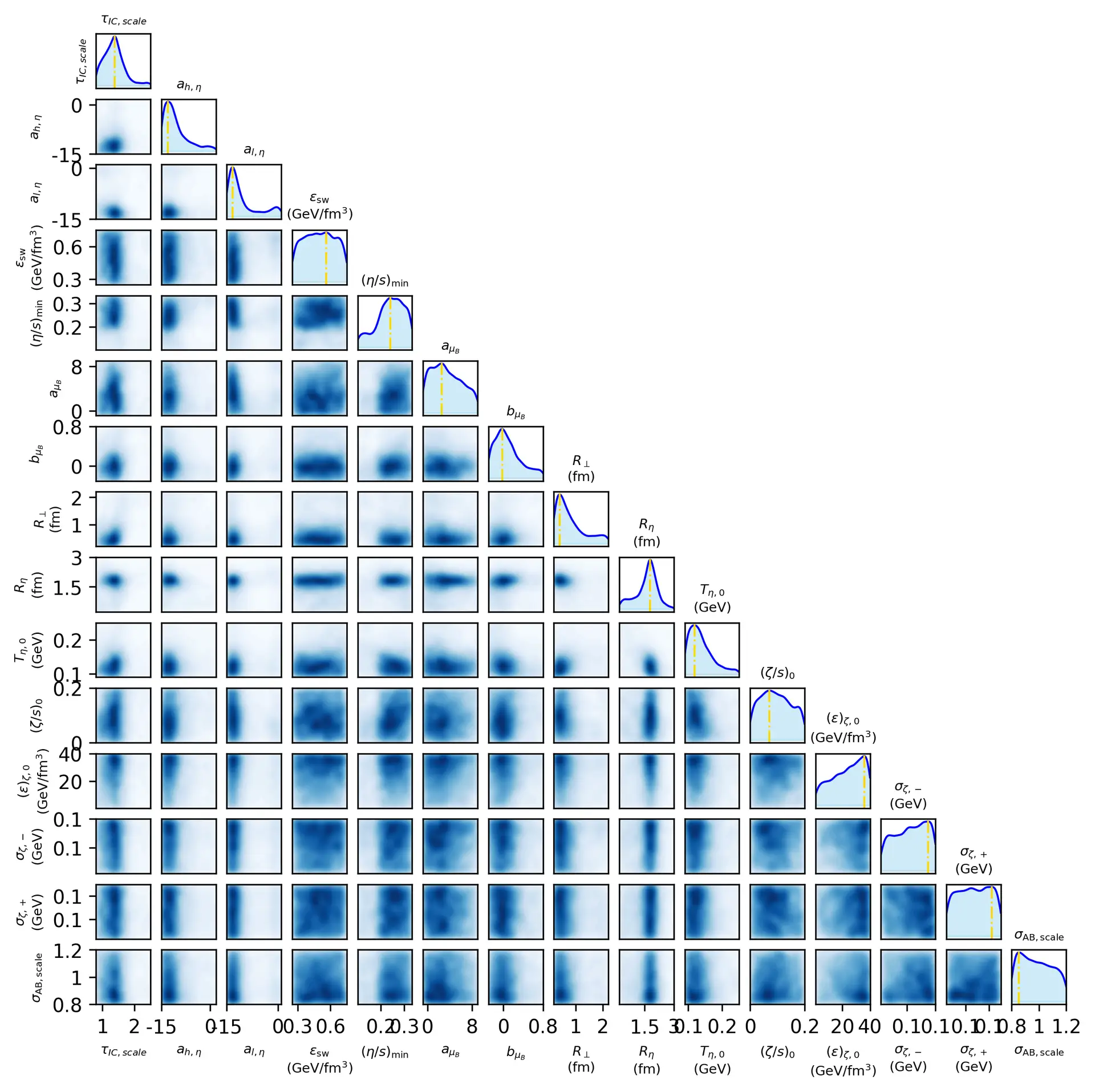
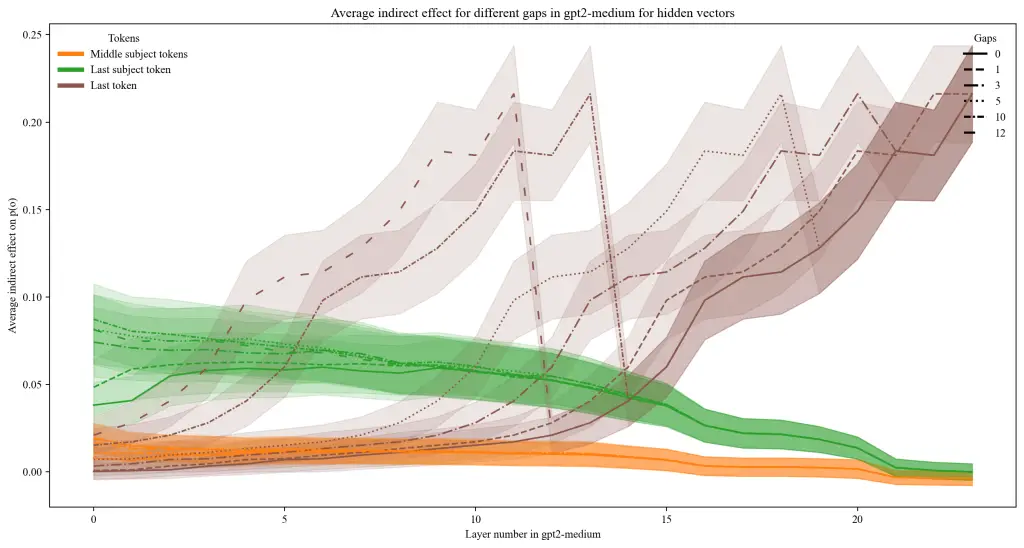
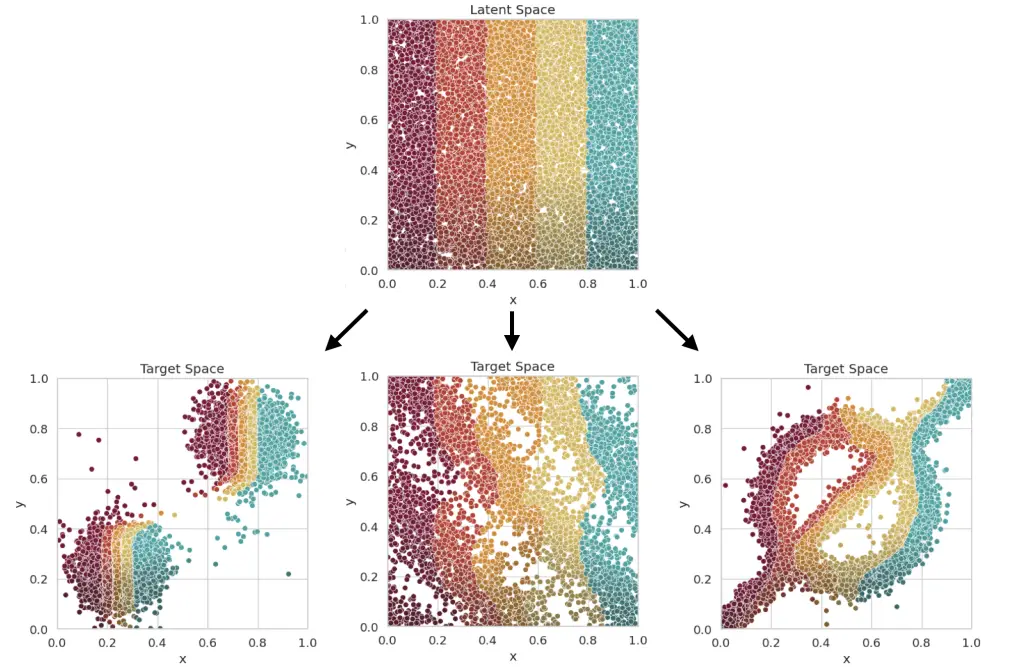
Welcome! I’m a physicist specializing in simulations, data science, and AI, with a PhD from Frankfurt on transport phenomena in heavy-ion collisions. My path—from international research to open science and climate advocacy—merges deep analytical thinking with a drive for real-world impact. Here, I share projects, publications, and ideas at the intersection of physics, machine learning, and responsible innovation.