Project Highlights and Insights
Explore some of my key projects and work experiences below. Each tab reveals objectives, methods, and outcomes for a deeper understanding of my work. Let’s delve into the details.
Bayesian Inference
State-of-the-art statistical analysis of vast datasets for model tuning. This project was one of the core achievements of my dissertation.
ZüNIS
Leveraging normalizing flows for faster integration of particle collision cross sections.
Causal Tracing

SPARKX
Python package for analysis of heavy-ion collision data, optimized for easy data handling.
SMASH-hybrid
Suite for integrating software modules for high-performance computation of heavy-ion collisions.
AI climate advisor
Chatbot for science-based climate consulting, based on the most important scientific results.
Heidelberg Engineering
Internship at Heidelberg Engineering, a company developing ophtamological devices. I developed analysis software for retina scanners.
Senacor Technologies
Internship at Senacor Technologies. I developed a B2B communication plattform for a bank, in an highly agile environment.
d-fine
Internship at d-fine. I analysed the database of a major German bank, identifying and fixing inconsistencies.
Get in Touch!
If you’re looking for collaboration or have questions, I’d love to hear from you. Let’s connect and explore what we can achieve together.
By sending this form, you agree to my Terms of Service and Privacy Policy.
Bayesian Inference
In this project, I used Bayesian analysis to compare simulations of nuclear collisions — where matter reaches extreme temperatures and densities — with experimental data from heavy-ion experiments. These collisions create conditions similar to those of the early universe, offering insights into how matter behaved microseconds after the Big Bang.
To extract those insights, I built a full inference pipeline that linked large-scale simulations with modern statistical tools. We ran thousands of simulations with varied input parameters, trained surrogate models using Gaussian processes, and applied Bayesian inference to estimate the most likely physical conditions behind the observed data.
This project lies at the intersection of theoretical physics and data analysis. It required handling uncertainty, navigating high-dimensional parameter spaces, and developing tools to connect models with reality. The techniques I used—such as statistical learning, dimensionality reduction, and surrogate modeling—are widely applicable to complex data challenges in and beyond science.
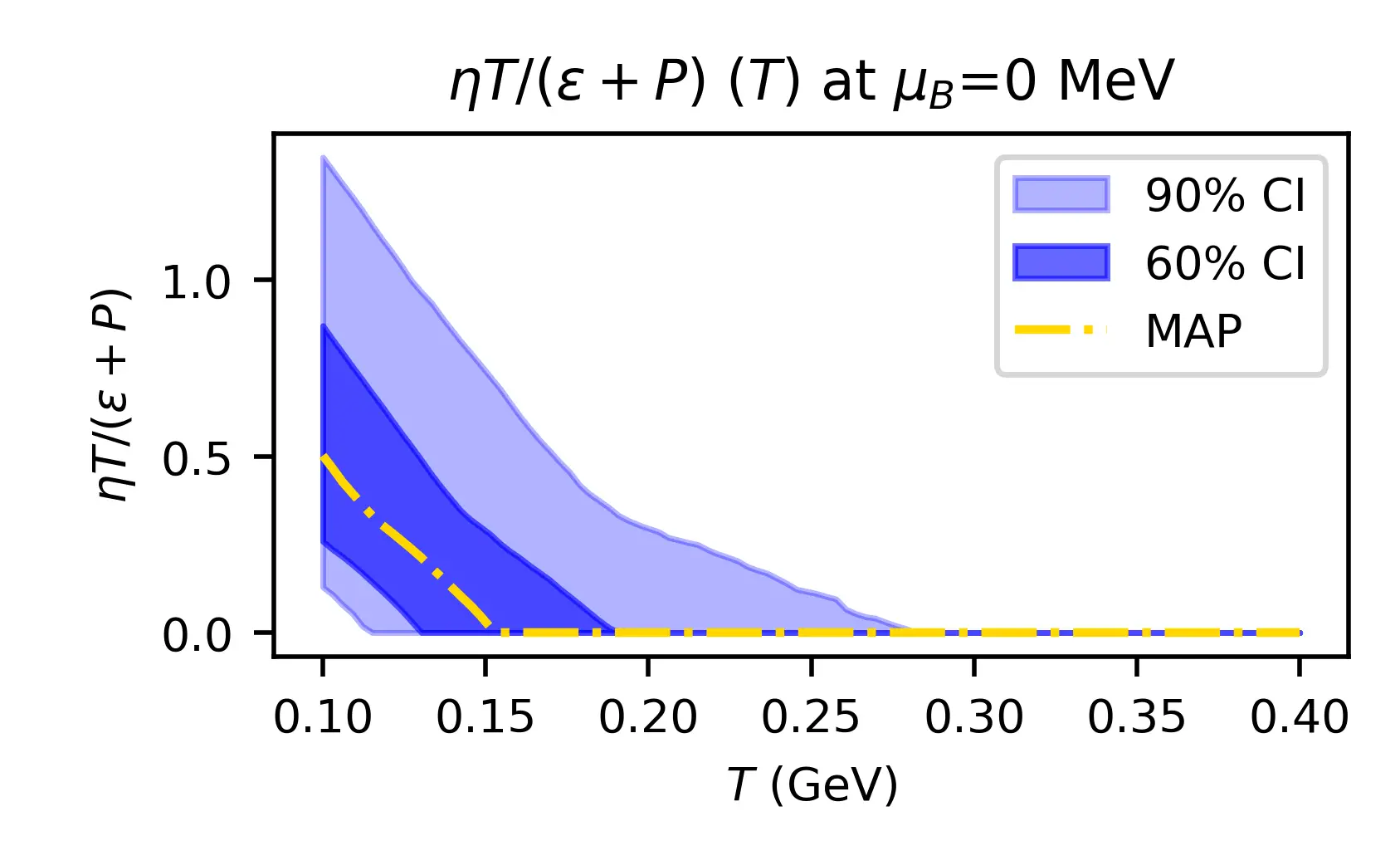
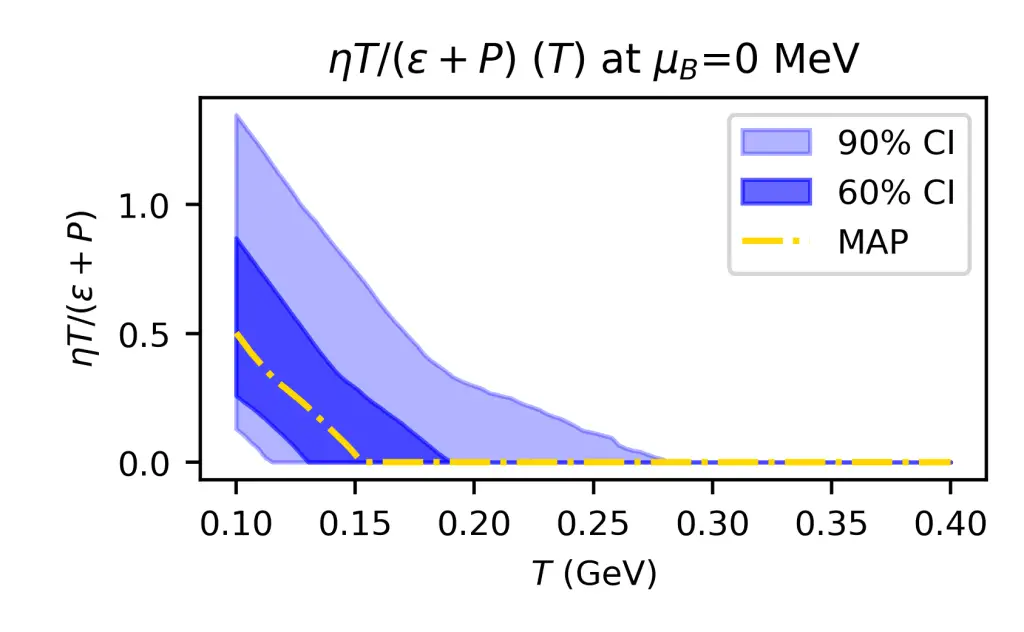
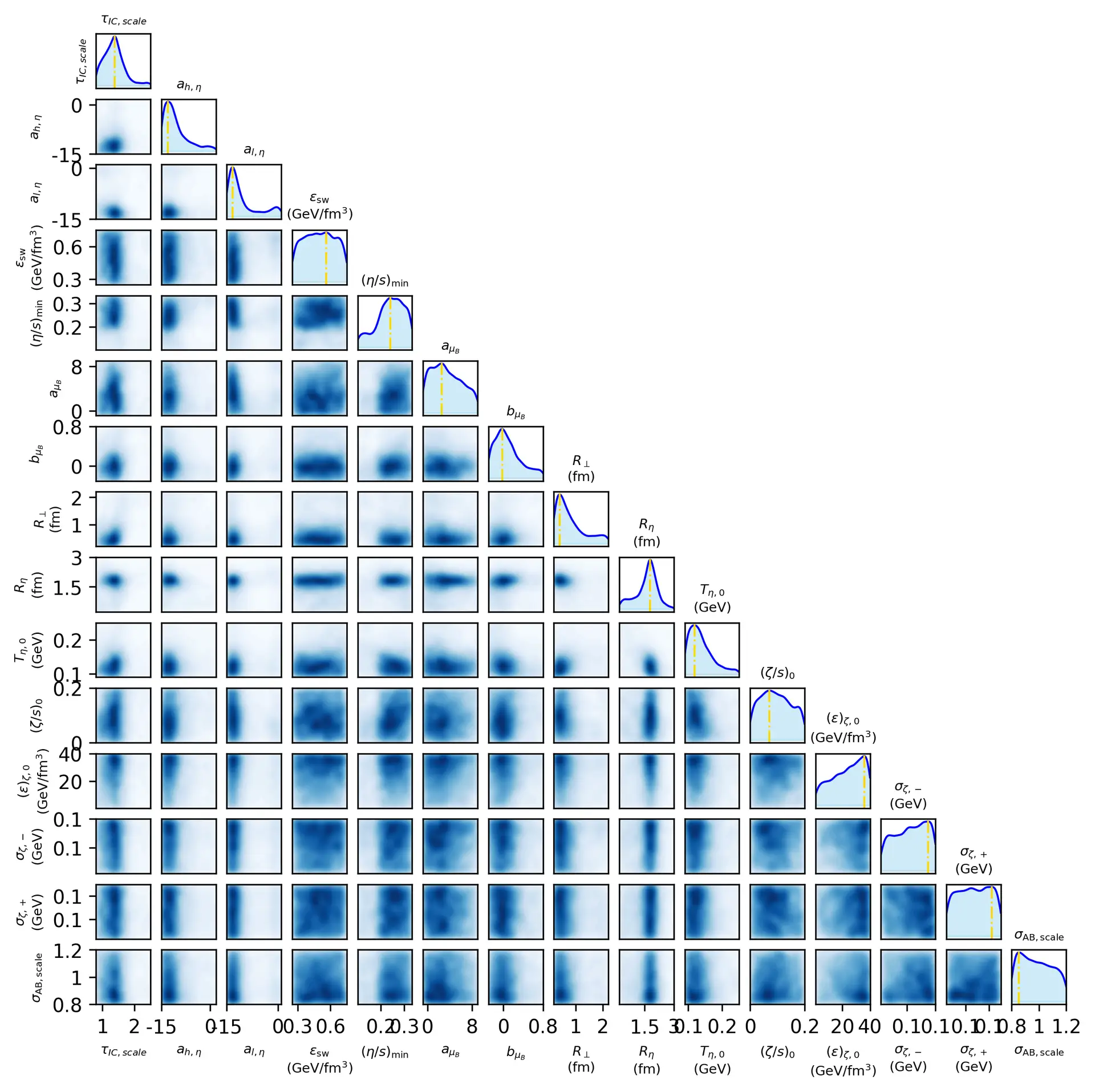
In the pictures, you can see on the top hand the result of our prediction of the viscosity of nuclear matter, as a function of the temperature. Our model predicts rapidly decreasing viscosity, in contrast to most other models on the market. This reveals substantial residual theory uncertainty. On the bottom, one can see the full posterior of all model parameters, allowing one to study correlations in the posterior.
Knowledge in LLMs
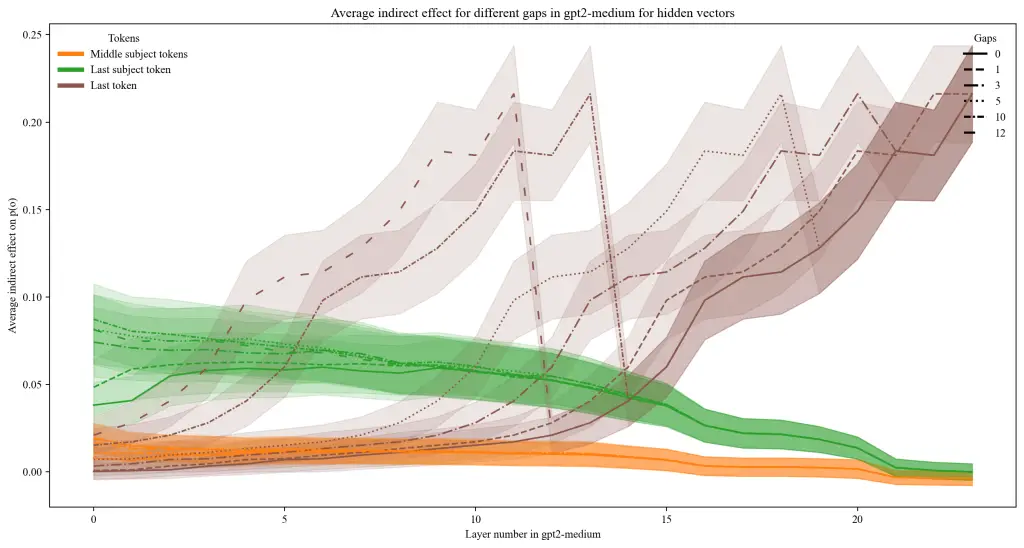
Large language models like ChatGPT appear to “know” all sorts of facts—from who the current president of France is to obscure trivia. But under the hood, these models are made up of hundreds of hidden layers of numbers and calculations. One of the big questions in AI safety and transparency is: Where exactly is that knowledge stored, and how does it move through the model?
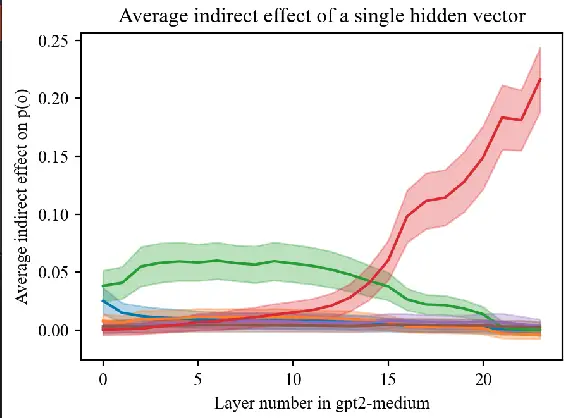
As part of the AI Safety Collab Germany 2024, I built a tool to investigate this question using a technique called causal tracing. It’s a bit like playing detective inside the AI: you mess with its input, and then trace which parts of its internal process are responsible for producing the correct answer. This helps pinpoint which layers or components are critical for factual knowledge.
What made my project unique—and helped it win the competition—was that I went beyond simply applying this method. I extended the method to trace how information flows across different layers and then analyzed whether there’s a consistent correlation between the activity of different layers when the model retrieves factual knowledge. This adds a new angle to understanding how knowledge is not just stored in one spot, but may be redundantly or cooperatively encoded across the model.
One of the core results is that while the final vector is the most crucial in restoring the information, the knowledge can be also substantially preserved when both restoring an early and a central layer. This points to new dynamics of information flow in LLMs which are yet to be studied. The notebook with all results is available online.
ML for MC integration
Almost all particle physics predictions are obtained by computing integrals like the cross section, many of which are calculated numerically using Monte Carlo methods. However, due to their complex structure this comes at an extremely high computational cost. Machine learning offers new ways to optimize the integration process, which significantly improves the success of methods like adaptive importance sampling beyond the capabilities of current approaches like VEGAS.
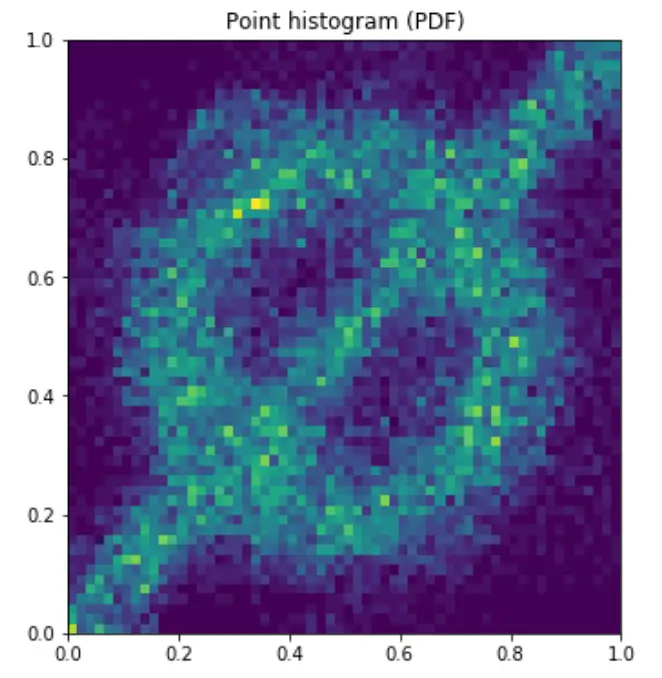
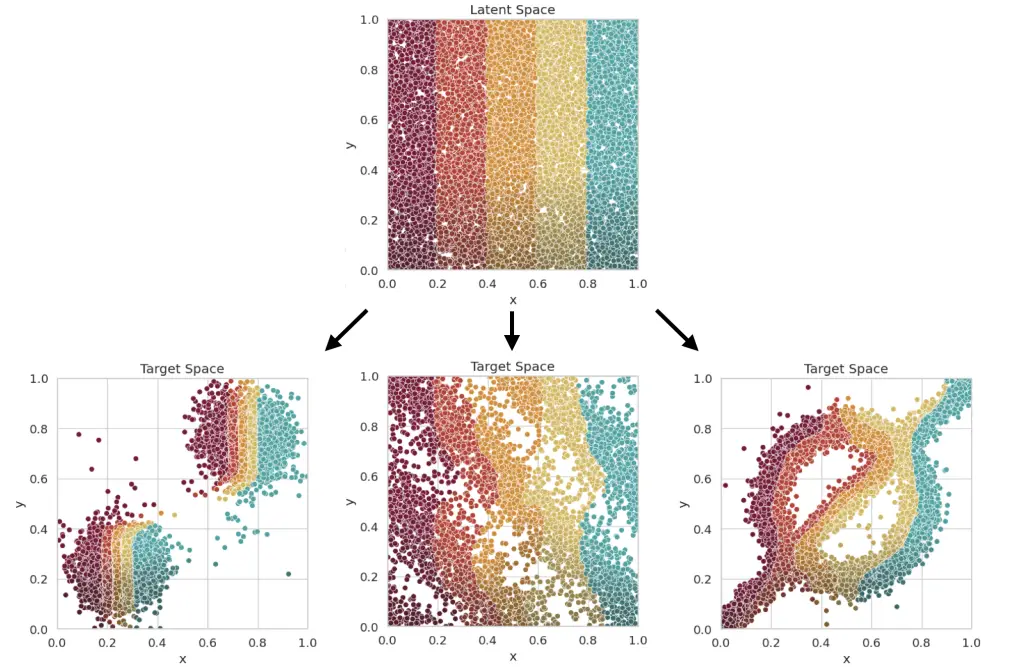
In my Master’s Thesis, I worked on Neural Importance Sampling. This method achieves a reduction of the variance of the integrator (and by this an improvement of the precision of the integral) by learning the optimal sampling of the latent variables. This is done by training a neural network which learns the optimal parameters of a normalizing flow. This normalizing flow transforms the originally uniformly distributed latent variables. The normalizing flows are realised using coupling cells, which contain the neural network which control the transformation. The mapping combination of multiple coupling cells determine the mapping, which is sketched in the lower right.
The advantage of this approach lies in the fact that it is adaptive and does not require any knowledge of the integrand. Together with a quasi-flat phase space generator, this allows fast integration also on a GPU architecture. Other than the very common adaptive approach VEGAS, this integration strategy does not fail for correlations along the integration axes. An example for this is the slashed circle function. The picture below shows how the Neural Importance Sampling learns different distributions. The VEGAS algorithm would not be able to learn this distribution efficiently as both axes are maximally correlated.
In my Master’s Thesis, I developed both multiple approaches of Neural Importance Sampling as well as a quasi-flat phase space generator. A demonstration of the strength of this approach is given in this demo jupyter notebook, which shows how to use the python package I developed.
I have continued my work on this promising approach by contributing to the ZüNIS package. A paper presenting the results with this novel method has been published in the reknown Journal of High Energy Physics.
SPARKX
SPARKX (Software Package for Analyzing Relativistic Kinematics in Collision eXperiments) is an open-source Python library for analyzing simulation data from heavy-ion collisions—an essential tool in theoretical nuclear physics. Unlike high-performance frameworks originally designed for experimental data, SPARKX focuses on accessibility and maintainability. It enables users to extract meaningful observables from common data formats like OSCAR and JETSCAPE within minutes, even with minimal Python experience.
As a core developer of SPARKX, I helped shape its design philosophy and implementation strategy. The project was driven by a simple but powerful observation: many researchers spend unnecessary time writing their own analysis scripts from scratch, which leads to duplicated effort, reduced reproducibility, and increased chances of error. SPARKX addresses this by offering a unified, cleanly structured alternative that supports a wide range of standard observables—without the steep learning curve.
The architecture of SPARKX is firmly grounded in object-oriented programming and the SOLID design principles:
Each module has a single responsibility, making the codebase intuitive to navigate and debug.
The design is open for extension but closed for modification, allowing users to add new file formats or physics routines without touching the core.
Interchangeable components (like different data loaders for OSCAR or JETSCAPE) are built to follow the Liskov Substitution Principle, ensuring consistency and reliability.
Specialized interfaces keep the code modular and decoupled, avoiding bloated, monolithic designs.
High-level modules depend on abstract contracts, not on implementation details, allowing flexibility in storage, analysis, and data access.
This structure made it possible to support complex workflows—like event-by-event flow calculations, anisotropic flow via Q-cumulants and Lee-Yang Zero methods, or jet observables—while keeping the system easy to test and extend.
Another pillar of the project is its emphasis on robustness. We implemented a comprehensive test suite using pytest, covering everything from individual algorithms to full analysis pipelines. Alongside this, we enforced static type checking with mypy, ensuring that data structures and method contracts remain consistent as the project evolves. These tools help protect against regressions and make onboarding of new contributors easier—crucial in academic environments with frequent team turnover.
SPARKX continues to grow. It is already used in multiple research workflows and is evolving to support performance enhancements such as parallelized analysis and C++ backend bindings. Through clean abstractions, transparent design, and strong testing discipline, it provides a stable foundation for high-quality scientific inference—and reduces the friction between raw data and insight.
SMASH-hybrid
As part of the development team behind the SMASH (Simulating Many Accelerated Strongly-interacting Hadrons) framework, I contributed to a codebase designed to simulate heavy-ion collisions at low and intermediate energies. SMASH is an open-source hadronic transport model developed to solve the relativistic Boltzmann equation via binary interactions, including resonances and string dynamics. In this setting, ensuring the physical integrity of the model goes hand in hand with rigorous attention to software quality — including traceable issue tracking, consistent versioning, comprehensive documentation, and systematic validation.
My main area of focus was extending SMASH through the hybrid approach, a methodology that connects hadronic transport with hydrodynamic evolution for high-energy collisions. This introduces the challenge of coordinating independently developed modules—each using different representations of matter and simulation states—into a single, robust pipeline. The orchestration logic must remain stable even under the pressure of extensive, high-statistics calculations and long execution times on HPC systems.
To meet this challenge, I lead the revamp of the SMASH-hybrid infrastructure. I have implemented a complete restructuring of the interface logic, replacing the static and restrictive CMake-based setup with a modular, script-driven framework. The new hybrid manager, written in Bash, is a configuration-based handler that enables reproducible, flexible execution across all simulation stages. Each stage is described via YAML-based inputs, enabling seamless integration of external modules such as vHLLE and particlization tools.
This redesign offers several key improvements:
-
Robust coordination of disparate simulation stages through integration-operation segregation logic.
-
Automated configuration validation, preventing misconfigured stages from wasting computational resources.
-
Reproducible workflows with structured outputs and version-tracked dependencies.
-
Easy extensibility, allowing new modules (e.g. alternative samplers like FIST) to be integrated with minimal changes.
-
Support for advanced studies, including full-featured parameter scans for Bayesian inference.
The result is a modular, maintainable, and user-friendly framework that facilitates both large-scale research projects and onboarding of new contributors, regardless of prior experience with the internals of the hybrid model. This work has turned the SMASH-hybrid framework into a sustainable, high-utility tool for the heavy-ion physics community.
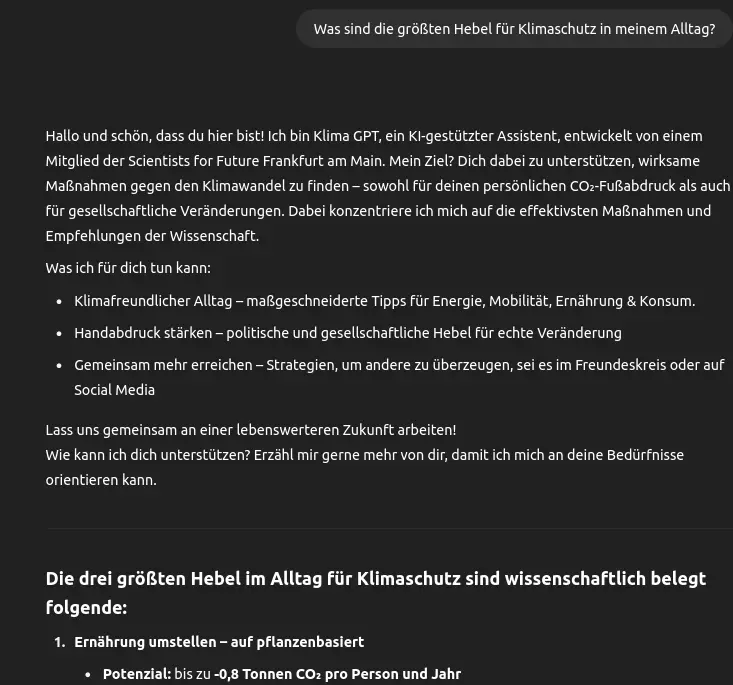
AI-powered guidance for sustainable action, grounded in science
As part of my work with Scientists for Future Frankfurt, I’ve been developing a custom AI chatbot that offers reliable, region-specific advice on climate action—specifically tailored to people living in Germany. Unlike generic AI tools, this chatbot is built on a curated knowledge base drawn from peer-reviewed publications and the Scientists for Future network. The result: informed, actionable responses without the noise, hallucinations, or superficiality common in open web searches.
The chatbot covers a wide range of topics, from energy and food systems to mobility, circular economy, and political engagement. It doesn’t just answer questions—it links related ideas, suggests concrete next steps, and encourages users to think beyond their personal footprint by promoting broader systemic impact (their so-called “handprint”).
Key Features:
Localized Intelligence: The chatbot uses regional data and policy knowledge to tailor advice for users across Germany.
Scientific Integrity: All core content is manually vetted and based on authoritative sources—no scraping from unreliable websites.
Action-Oriented Responses: Every reply ends with 1–3 practical suggestions or prompts for deeper engagement.
Adaptable Communication: The chatbot adjusts its tone and reasoning based on user input—supporting everything from personal lifestyle changes to political argumentation.
Built for Reach: It can engage with unlimited users at once, offering scalable climate communication far beyond what personal consultations can achieve.
Under the Hood:
A topic-triggering system prioritizes relevant insights based on keywords like “electricity mix” or “mobility transition.”
Clear instruction sets define tone, structure, and emphasis in responses.
The backend is designed to be modular and testable, allowing future integration with tools like CO₂ calculators.
Status & Outlook:
A structured proof-of-concept is in place, with initial content on energy, heating, and food.
The next development steps include expanding the topic base, refining the dialogue logic, and improving real-world reliability through testing.
The project remains open to collaboration—especially with experts interested in contributing content or testers helping identify weak spots in interaction logic. Currently, a collaboration with a similiar project, called “The Activist Guide” is explored.
This chatbot is an experiment in using AI to amplify trusted knowledge, support systemic change, and bring climate expertise directly to where it’s needed: everyday decisions, conversations, and campaigns.
Retina Scanner Software
Exploring image registration and UI development in retinal diagnostics
During my internship at Heidelberg Engineering, I had the opportunity to lead two independent development projects related to retinal imaging.
In the first project, I worked in C++ to enhance the user interface of an internal software tool for retina scanners — integrating new visual components and improving existing structures for usability and maintainability.
The second project focused on the feasibility of improving image registration algorithms for retinal scans. I explored ways to better accommodate the specific curvature of the eye, and experimented with modern numerical techniques to reduce computation time while enabling more sophisticated transformation models. The goal was to evaluate whether higher-order geometric mappings could improve registration accuracy without compromising performance.
What made this internship particularly rewarding was the combination of technical depth and practical impact — bridging advanced algorithmic design with real-world clinical applications.
Agile Software Development
Full-Stack Development in a High-Responsibility Agile Team
During my internship at Senacor Technologies, I worked as a full-stack developer in a Scrum-based agile team, contributing to a business-to-business communication system for a mid-sized credit bank.
I was involved in both backend and frontend development, using Java with Spring Boot and Hibernate, and AngularJS for the client side. My responsibilities included writing unit tests (JUnit, Mockito), implementing behavior-driven development workflows using Cucumber, and managing databases with PostgreSQL. All tasks were coordinated via JIRA as part of a structured Scrum workflow with regular sprints and reviews.
The agile setting gave me both independence and strong team support. Due to high team turnover during my stay, I quickly took on additional responsibility — including onboarding and mentoring new interns, helping them become productive in a short time. This experience strengthened my ability to work autonomously while staying aligned with team goals.
Beyond hands-on coding, I gained valuable insight into:
-
Agile project planning and sprint-based iteration
-
Balancing time pressure with high code quality standards
-
Evaluating and justifying technology choices in a fast-moving development cycle
This internship not only improved my technical skills but also showed me how to contribute meaningfully within a professional, agile development environment.
Risk Consulting
Risk Consulting in Data-Driven Regulatory Projects
During my internship at d-fine, I joined a consulting team supporting a credit bank in the implementation of financial regulations, including the Internal Ratings-Based Approach (IRBA). This was a critical project phase tied to upcoming regulatory audits.
My responsibilities focused on data analysis and database consistency, using SQL and Excel daily to identify irregularities, interpret large datasets, and support model validation. I developed analytical models to trace and explain sources of errors in the database structure, and contributed to building sustainable solutions for data integrity and reporting.
Beyond the technical work, I gained first-hand experience with:
Project management under high-stakes conditions
Client communication and collaboration in a high-performance environment
The importance of resilience and precision in data-sensitive regulatory contexts
This internship gave me valuable insight into the intersection of data, finance, and compliance, while sharpening both my analytical and interpersonal skills under real-world pressure.
Imprint & Privacy Notice © Niklas Götz, 2025